

mysql 聚簇索引和非聚簇索引的区别
聚簇索引和非聚簇索引的区别:聚簇索引的叶子节点就是数据节点,而非聚簇索引的叶子节点仍然是索引节点,只不过有指向对应数据块的指针。
mysql 中不同的数据存储引擎对聚簇索引的支持不同,我们可以看一下 mysql 中 myisam 和 innodb 两种引擎的索引结构。
假如原始数据如下:
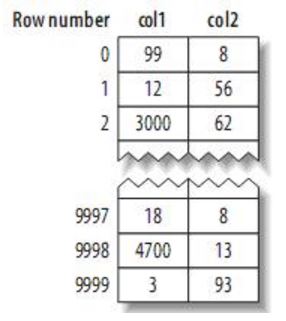
1. myisam 引擎的数据存储方式
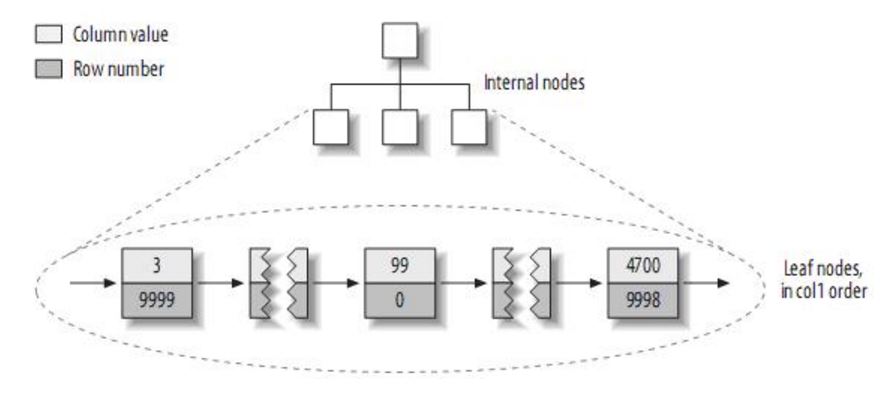
myisam 是按列值与行号来组织索引的。它的叶子节点中保存的实际上是指向存放数据的物理块的指针。从 myisam 存储的物理文件我们能看出,myisam 引擎的索引文件(.myi)和数据文件(.myd)是相互独立的。
2. innodb 引擎的数据存储方式
innodb 按聚簇索引的形式存储数据,所以它的数据布局有着很大的不同。
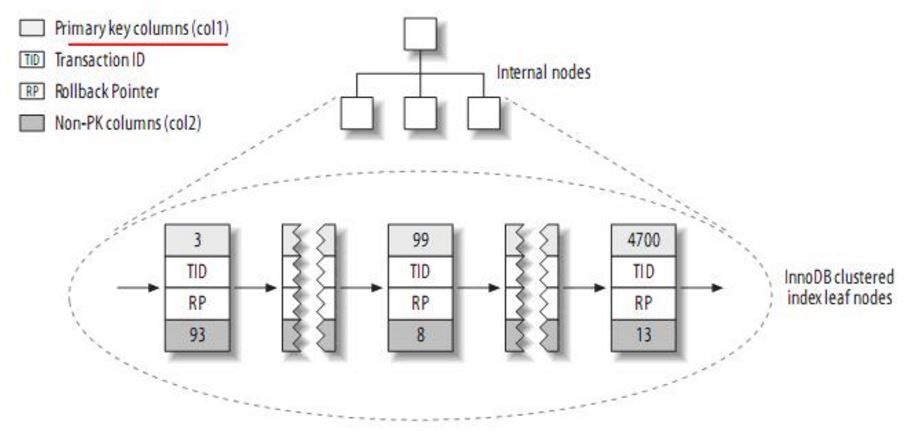
聚簇索引中的每个叶子节点包含主键值、事务id、回滚指针(rollback pointer用于事务和mvcc)和余下的列(如col2)。
innodb 的二级索引与主键索引有很大的不同。innodb 的二级索引的叶子包含主键值,而不是行指针(row pointers),这减小了移动数据或者数据页面分裂时维护二级索引的开销,因为 innodb 不需要更新索引的行指针。其结构大致如下:
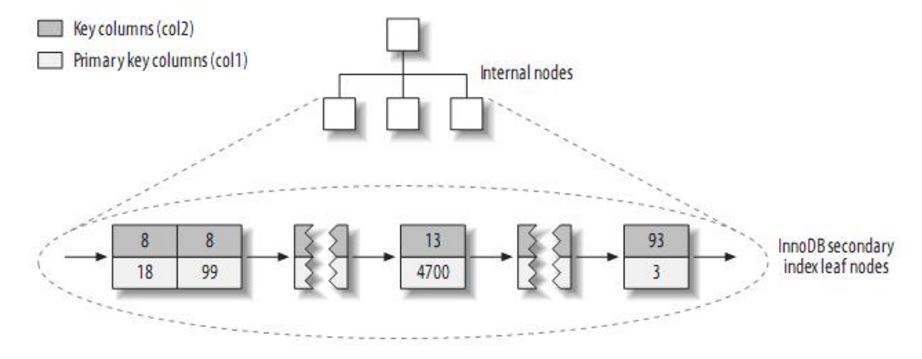
innodb和myisam的主键索引与二级索引的对比: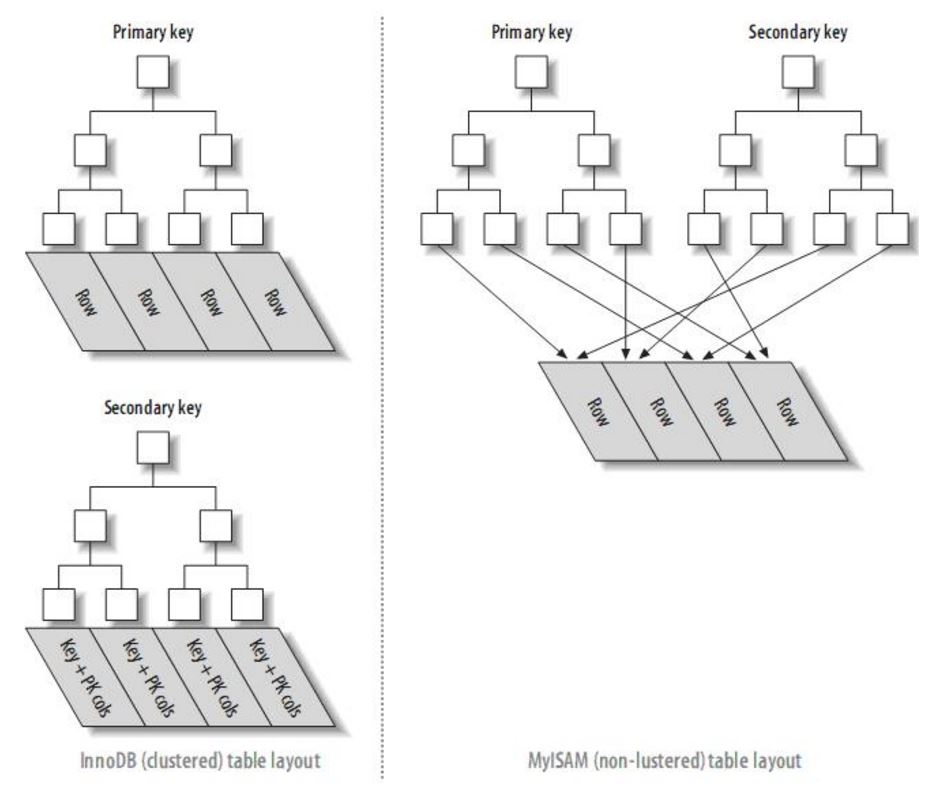
innodb的的二级索引的叶子节点存放的是key字段加主键值。因此,通过二级索引查询首先查到是主键值,然后innodb再根据查到的主键值通过主键索引找到相应的数据块。而myisam的二级索引叶子节点存放的还是列值与行号的组合,叶子节点中保存的是数据的物理地址。所以可以看出myisam的主键索引和二级索引没有任何区别,主键索引仅仅只是一个叫做primary的唯一、非空的索引,且myisam引擎中可以不设主键。
3. 聚簇索引的优缺点
优点:
- 可以把相关数据保存在一起,数据访问就更快。
- 聚簇索引将索引和数据保存在同一个b-tree中,因此获取数据比非聚簇索引要更快。
- 使用聚簇索引扫描的查询可以直接使用页节点中的主键值。
缺点:
- 聚簇索引最大程度提高了io密集型应用的性能,如果数据全部在内存中将失去优势。
- 更新聚簇索引列的代价很高,因为会强制每个被更新的行移动到新位置。
- 基于聚簇索引的表插入新行或主键被更新导致行移动时,可能导致页分裂,表会占用更多磁盘空间。
- 当行稀疏或由于页分裂导致数据存储不连续时,全表扫描可能很慢。
4. 创建索引示例
建立索引之前选好表对象,假设表名为 indextesttable,此表中包含三个字段 id,name,uniquecode。为了更快的进行姓名查询,我们可以在 name 字段上添加非聚簇索引。
创建索引的格式如下:
create nonclustered index [index_name【索引名称】] on [table_name【表名称】]([column_name1【列名称】],[column_name2【列名称】],...);
我们给 indextesttable 表的 name 字段添加一个非聚簇索引:
create nonclustered index indextesttable_index_name on indextesttable(name);
给 indextesttable 表的 uniquecode 字段添加一个聚簇索引:
create clustered index indextesttable_index_uniquecode on indextesttable(uniquecode)
这是最简单最直接的设置索引的方式,而通常实际应用中,会有多字段联合添加索引的情况,这个就需要根据实际的应用查询场景,以及在 where 条件下最常用的查询字段。
例如:在 tablex 中你最经常查询的条件:
select name,message from tablex where 1=1 and deptid='003523' and limitedcondition='somevalue'
这个时候你就可以 添加一个基于 deptid 和 limitedcondition 两个字段的非聚簇索引,以便于加速查询速度。
create nonclustered index tablex_index_departid_limitedcondition on tablex(deptid,limitedcondition);
 学习MySQL
学习MySQL