

关于.net环境下跨进程、高频率读写数据的问题
一、需求背景
1、最近项目要求高频次地读写数据,数据量也不是很大,多表总共加起来在百万条上下。
单表最大的也在25万左右,历史数据表因为不涉及所以不用考虑,
难点在于这个规模的热点数据,变化非常频繁。
数据来源于一些检测设备的采集数据,一些大表,有可能在极短时间内(如几秒钟)可能大部分都会变化,
而且主程序也有一些后台服务需要不断轮询、读写某种类型的设备,所以要求信息交互时间尽可能短。
2、之前的解决方案是把所有热点数据,统一加载到共享内存里边,到也能够支撑的住(毫秒级的),但是由于系统架构升级,之前的程序(20年前的)不能兼容。
只能重新写一个,最先想到的是用redis,当时把所有api重写完成后,测试发现效率不行,是的,你没有看错,redis也是有使用范围的。
3、redis读写非常快,但是对于大批量读写操作我觉得支持不够,虽然redis支持批量读写,但是效率还是不够快,
对于字符串(string)类型的批量读写,我测试过;效率比较好的在每批次200 至 250条之间,处理20万条数据耗时5秒左右, (pc机,8g,4核)
而对于有序集合(sorted set)类型,批量写的操作用起来非常别扭,而且没有修改api(如有其他方式请指教),我测试过,效率没string类型那么高
其他类型不适合我的业务场景,就没考虑使用了
4、所以项目组最后决定还是用回共享内存,先决定在.net环境下使用c#的共享内存,这个功能可能使用的人不多,其实在.net4.0版本就已经集成进来了
在system.io.memorymappedfile命名空间下。这个类库让人很无语,因为里边能用的只有write、read这2种方法,而且只是针对字节的操作,
需要非常多的类型转换,非常麻烦!想想,只能以字节为单位去构建一个需要存放百万级数据的内存数据库,得多麻烦?
需要手动搞定索引功能,因为要支持各种查询,最后花了一天的时间写完demo,最后测试后发现效率并没有很大提高,因为当时加了互斥量测试,
但是离毫秒级差得远。这个技术点有兴趣的可以了解下,园子里有,如:https://www.cnblogs.com/zeroone/archive/2012/04/18/2454776.html
二、没错,第一节写的太多了
1、最后分析,这应该是c#语言的瓶颈,c#对于这种骚操作是不那么成熟的。
2、最后瞄来瞄去,决定使用vc开发一个dll,在里边封装对内存数据的读写功能,然后c#调用
3、本人的c、c++不那么熟、参考了一些实例,比如园子里的:http://www.cnblogs.com/cwbcwb505/archive/2008/12/08/1350505.html
4、是的,你没有看错,2008年的,我还看到一篇更早的,看来底层开发c、c++那么经久不衰不是没有道理的,很多技术现在都在用
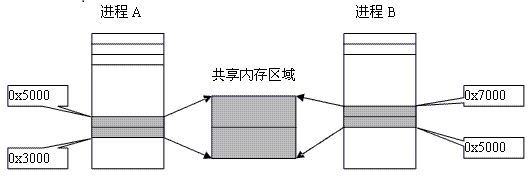
5、看看什么是共享内存
三、开始写代码了
1、首先建2个控制台项目,支持mfc,
2、先这样:一个负责创建共享内存,初始化数据
3、再这样:一个读写数据测试,最后修改
4、最后修改下图片细节,测试一下,看看效果

5、完成了,see, 是不是很简单呀?都会了吗?

四、真的要贴代码了
1、先定义个枚举返回状态
typedef enum
{
success = 0,
alreadyexists = 1,
error = 2,
oversize = 3
}enummemory;
2、再定义个结构体用来测试
typedef struct
{
int tagid;
char tagname[32];
int area;
double engval;
double updatetime;
double rawmax;
double rawmin;
double rawval;
char name[50];
char al;
double astime;
char maskstate;
double amtime;
char cf;
char tdf;
char alarmcode[32];
}teng;
3、开始创建共享内存
int create(uint size)
{
// data
handle filemap = createfilemapping(invalid_handle_value, null, page_readwrite, 0, size, “name”);
if (filemap == null || filemap == invalid_handle_value)
return error;
if (getlasterror() == error_already_exists)
return alreadyexists;
// init
void *mapview = mapviewoffile(filemap, file_map_write, 0, 0, size);
if (mapview == null)
return error;
else
memset(mapview, 0, size);
return success;
}
4、再开始写数据
int write(void *pdate, uint nsize, uint offset)
{
// open
handle filemap = openfilemapping(file_map_write, false, “name”);
if (filemap == null)
return error;
// hander
void *mapview = mapviewoffile(filemap, file_map_write, 0, 0, nsize);
if (mapview == null)
return error;
else
writedataptr = mapview;
// write
memcpy(mapview, pdate, nsize);
unmapviewoffile(pmapview);
return success;
}
5、开始读数据
int read(void *pdata, uint nsize, uint offset)
{
// open
handle filemap = openfilemapping(file_map_read, false, gettablename());
if (filemap == null)
return error;
// hander
void *pmapview = mapviewoffile(filemap, file_map_read, 0, 0, nsize);
if (pmapview == null)
return error;
else
readdataptr = pmapview;
memcpy(pdata, (pmapview, nsize);
unmapviewoffile(pmapview);
return success;
}
6、ok了,不复杂,网上都有这些资料,最后我们贴上测试程序
int _tmain(int argc, tchar* argv[], tchar* envp[])
{
int length = 100000;
ceng * ceng = new ceng();
dword dwstart = gettickcount();
for (int i = 0; i < length; i++) {
teng eng;
ceng->read(&eng, ceng->size, ceng->size * i);
eng.engval = i;
ceng->write(&eng, ceng->size, (i*ceng->size));
if (i % 10000 == 0 || i == length - 1)
printf("正在读写的eng.tagname:%s \n", eng.tagname);
}
printf("总条数%d,耗时:%d 毫秒 \n", length, gettickcount() - dwstart);
// 验证数据
teng eng5000;
ceng->read(&eng5000, ceng->size, ceng->size * 5000);
printf("\n验证数据 \n");
printf("第5000个eng的tagid:%d, engval:%lf \n", eng5000.tagid, eng5000.engval);
scanf_s("按任意键结束");
return 0;
}
7、还有写测试程序
int _tmain(int argc, tchar* argv[], tchar* envp[])
{
int length = 100000;
ceng * ceng = new ceng();
ceng->create(ceng->size * length);
dword dwstart = gettickcount();
for (int i = 0; i < length; i++)
{
teng eng;
memset(&eng, 0, ceng->size);
eng.tagid = i;
sprintf_s(eng.alarmcode, "alarmcode.%d", i);
sprintf_s(eng.tagname, "tagname.%d", i);
if (i % 10000 == 0 || i == length - 1)
printf("正在写入的eng.tagname:%s \n", eng.tagname);
ceng->write(&eng, ceng->size, (i*ceng->size));
}
// print time
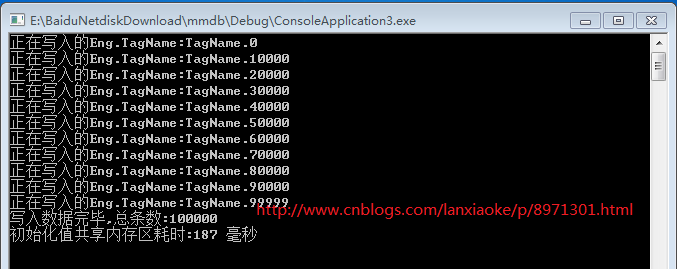
printf("写入数据完毕,总条数:%d\n", length);
printf("初始化值共享内存区耗时:%d 毫秒 \n", gettickcount() - dwstart);
scanf_s("按任意键结束");
return 0;
}
8、当然得再贴一遍啦
五、差点忘记做成dll了
1、定义外部函数
extern "c" __declspec(dllexport) int readfromsharedmemory(teng *pdata, int nsize, int offset)
{
return ceng->read(pdata, nsize, offset);
}
extern "c" __declspec(dllexport) int writetosharedmemory(void *pdata, int nsize, int offset)
{
return ceng->write(pdata, nsize, offset);
}
2、好了,vc到此为止,可以去领盒饭了,c#进场
public class lib
{
[dllimport("consoleapplication4.dll", callingconvention = callingconvention.cdecl)]
public static extern int readfromsharedmemory(intptr pdata, int nsize, int offset);
[dllimport("consoleapplication4.dll", callingconvention = callingconvention.cdecl)]
public static extern int writetosharedmemory(intptr pdata, int nsize, int offset);
}
3、c#测试一下
static void main(string[] args)
{
var length = 100000;
var starttime = datetime.now;
var size = marshal.sizeof(typeof(teng));
var intptrout = marshal.allochglobal(size);
var intptrin = marshal.allochglobal(size);
for (var i = 0; i < length; i++)
{
lib.readfromsharedmemory(intptrout, size, size * i);
var eng = marshal.ptrtostructure<teng>(intptrout);
eng.engval = i;
marshal.structuretoptr(eng, intptrin, true);
lib.writetosharedmemory(intptrin, size, size * i);
if (i % 10000 == 0)
console.writeline("eng.tagid:{0}", eng.tagid);
}
console.writeline("总条数{0},耗时:{1} 毫秒", length.tostring(),
(datetime.now - starttime).totalmilliseconds.tostring());
// 验证数据
var intptr100 = marshal.allochglobal(size);
lib.readfromsharedmemory(intptr100, size, size * 100);
var eng100 = marshal.ptrtostructure<teng>(intptr100);
console.writeline();
console.writeline("验证数据");
console.writeline("第100个eng的tagid:{0},engval:{1}", eng100.tagid, eng100.engval);
console.readkey();
}

4、165毫秒,相比在vc下运行,差了一个数量级,但是,也不错了;
因为c#环境下需要不断的marshal.ptrtostructure、marshal.structuretoptr,频繁地把数据在托管内存俞共享内存之间搬运
是需要耗费时间的,这点有更好处理方式的请指教,
六、因为跨线程、进程,所以要考虑加入互斥量哦
1、很简单,mfc下有现成的类cmutex,加在write里边在看看效率
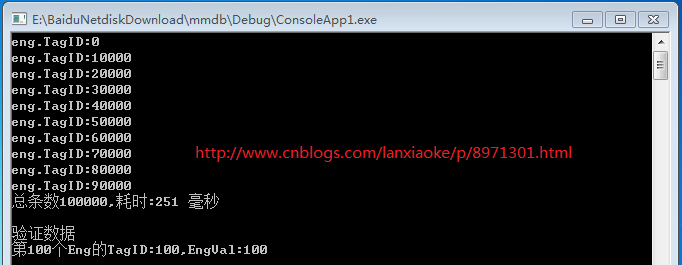
互斥量是需要耗费资源的,多了将进100毫秒
2、读写都加上互斥量试试看
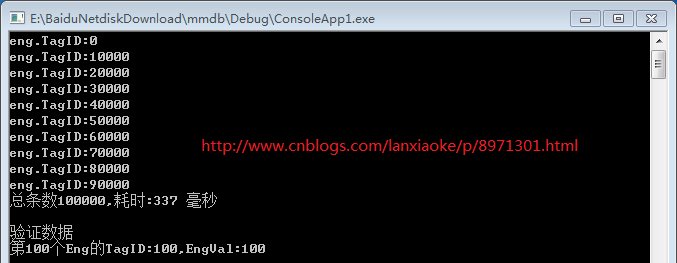
又多了80多毫秒,
鱼与熊掌不可兼得啊。要根据实际运用场景觉得是否加上互斥量
好了,人家51去游玩、我却宅家里码程序,可见我的趣味还是挺高的,洗澡、洗衣服、然后去吃饭、一天没进食了,
以上就是.net环境下跨进程、高频率读写数据的详细内容,更多关于.net跨进程高频率读写数据的资料请关注硕编程其它相关文章!
 C++实战
C++实战